Архитектурный анализ межпроцессорной связи серверов
Архитектурный анализ серверов на базе AMD 9005
Рассмотрим два дизайна серверов:
- 2 процессора AMD 9005 (CPU_0 и CPU_1), от каждого процессора разведено 5 слотов PCIe x16, в слоты от CPU_0 установлена 4 ускорителя Nvidia H200 NVL, они объединены мостами NVLink 4-post, а так же адаптер Infiniband 400Gbps, в слоты от CPU_1 установлена 4 ускорителя Nvidia H200 NVL, они объединены мостами NVLink 4-post, а так же адаптер Infiniband 400Gbps, таким образом у нас всего 8 ускорителей Nvidia H200 NVL и два адаптера Infiniband 400Gbps.
- 2 процессора AMD 9005 (CPU_0 и CPU_1), к каждому процессору подключен PCIe Switch Broadcom PEX89144 (BR_0 и BR_1 соответственно), подключение BR к CPU выполнено PCIe5 x16. От коммутатора BR_0 и BR_1 разведено 5 слотов PCIe x16, в слоты от BR_0 установлена 4 ускорителя Nvidia H200 NVL, они объединены мостами NVLink 4-post, а так же адаптер Infiniband 400Gbps, в слоты от BR_1 установлена 4 ускорителя Nvidia H200 NVL, они объединены мостами NVLink 4-post, а так же адаптер Infiniband 400Gbps, таким образом у нас всего 8 ускорителей Nvidia H200 NVL и два адаптера Infiniband 400Gbps.
Краткий вывод
Дизайн 1 (прямое подключение к CPU) является более оптимальным решением для задач инференса и fine-tuning больших моделей, требующих взаимодействия между двумя группами GPU. Прямое подключение через CPU обеспечивает более низкую латентность (15-25 мкс против 2-5 мкс через InfiniBand), лучшую интеграцию с технологиями GPUDirect и упрощённую топологию для tensor parallelism и pipeline parallelism.
Детальное сравнение архитектур
Дизайн 1: Прямое подключение GPU к CPU
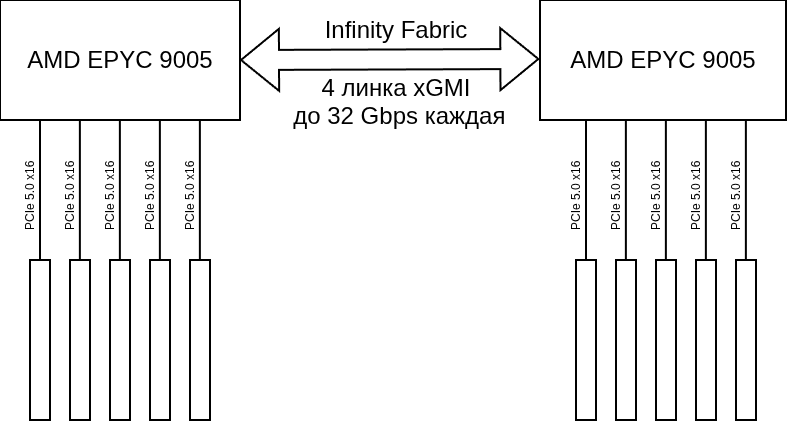
Архитектура:
- CPU_0 и CPU_1 AMD EPYC 9005, каждый с 5 слотами PCIe 5.0 x16
- 4x H200 NVL подключены к CPU_0, объединены NVLink 4-post
- 4x H200 NVL подключены к CPU_1, объединены NVLink 4-post
- 2x InfiniBand 400Gbps адаптера (по одному на каждый CPU)
- Межсокетное соединение через Infinity Fabric (4 линка xGMI до 32 Gbps каждая)
Пропускная способность:
Процессоры AMD EPYC 9005 поддерживают до 128 PCIe Gen 5.0 линий в односокетной конфигурации и до 160 в двухсокетной. В двухсокетной системе часть линий используется для межсокетных Infinity Fabric подключений (обычно 64 линии или 4 линка x16), оставляя 64 линии PCIe на каждый процессор.
Внутри каждой группы из 4 GPU:
- NVLink 4-way bridge: до 1.8 TB/s агрегированной пропускной способности на группу
- Каждый GPU H200 NVL имеет 900 GB/s NVLink bandwidth
- PCIe Gen5 x16: 128 GB/s на GPU для связи с CPU
Между двумя группами GPU (через CPU):
- PCIe Gen5 x16: 128 GB/s от GPU к CPU (64 GB/s в каждом направлении)
- Infinity Fabric между сокетами: приблизительно 37.9-42.6 GB/s агрегированной двунаправленной пропускной способности при использовании 4 линков
- Латентность межсокетного взаимодействия: 130-241 нс
Дизайн 2: PCIe коммутаторы
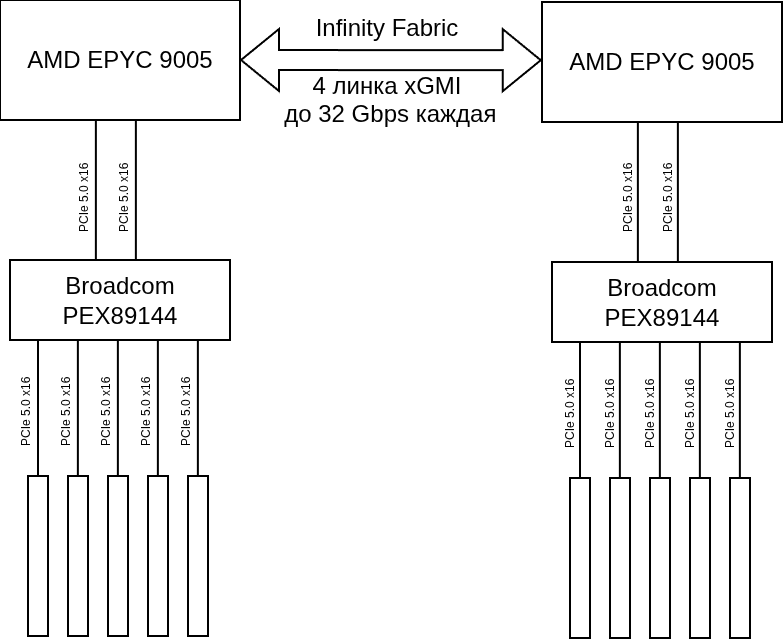
Архитектура:
- CPU_0 и CPU_1 AMD EPYC 9005
- PCIe Switch Broadcom PEX89144 (BR_0 и BR_1) подключены к CPU через PCIe5 x16
- От каждого коммутатора разведено 5 слотов PCIe x16
- 4x H200 NVL подключены к BR_0, объединены NVLink 4-post
- 4x H200 NVL подключены к BR_1, объединены NVLink 4-post
- 2x InfiniBand 400Gbps адаптера
Пропускная способность:
PEX89144 — это 144-линейный коммутатор PCIe Gen 5.0 с максимальной сырой пропускной способностью до 9,216 TB/s через все порты. Однако каждое upstream-подключение к CPU ограничено одной линком PCIe5 x16 (128 GB/s или 64 GB/s в каждом направлении).
Внутри каждой группы из 4 GPU:
- NVLink 4-way bridge: до 1.8 TB/s (идентично Дизайну 1)
Между двумя группами GPU (через PCIe Switch и CPU):
-
PCIe Gen5 x16: 128 GB/s от коммутатора BR_0 к CPU_0
-
Infinity Fabric между CPU: 37.9-42.6 GB/s
-
PCIe Gen5 x16: 128 GB/s от CPU_1 к коммутатору BR_1
-
Дополнительная латентность коммутатора: 100-120 нс на каждый hop через PEX switch
-
Общая латентность: ~400-500 нс (две traversal через switches + межсокетная латентность + передача данных)
Сильные и слабые стороны
Дизайн 1: Прямое подключение к CPU
Сильные стороны:
- Минимальная латентность для GPU-to-GPU через сокеты: 15-25 мкс при использовании GPUDirect RDMA через PCIe
- Упрощённая топология: меньше компонентов в data path означает меньше точек отказа и проще отладка
- Оптимальная поддержка GPUDirect RDMA: прямой путь от GPU к InfiniBand адаптеру без промежуточных коммутаторов обеспечивает лучшую производительность GPUDirect
- Полоса пропускания PCIe доступна напрямую: каждый GPU имеет прямой доступ к полной пропускной способности PCIe x16 без конкуренции внутри коммутатора
- Лучшая производительность для tensor parallelism: прямое соединение через CPU с Infinity Fabric минимизирует латентность для синхронизации между GPU группами
Слабые стороны:
- Ограничение по количеству линий PCIe: процессор должен распределить PCIe линии между GPU и другими устройствами, что может ограничить расширяемость
- Bottleneck Infinity Fabric: пропускная способность между сокетами (37.9-42.6 GB/s) значительно ниже, чем NVLink (1.8 TB/s)
- NUMA эффекты: неравномерный доступ к памяти может повлиять на производительность
- Сложность проектирования PCB: требует тщательной разводки PCIe линий на материнской плате
Дизайн 2: PCIe коммутаторы
Сильные стороны:
- Гибкость конфигурации: PCIe коммутатор позволяет более гибко распределять линии между устройствами
- Масштабируемость: легче добавить дополнительные устройства без изменения CPU конфигурации
- Снижение нагрузки на PCIe линии CPU: CPU освобождается от необходимости напрямую управлять всеми GPU подключениями
- Потенциально лучшая балансировка нагрузки: коммутатор может динамически распределять bandwidth между портами
Слабые стороны:
- Увеличенная латентность: добавление PCIe коммутатора добавляет 100-120 нс латентности на каждый hop
- Bottleneck upstream подключения: все 4 GPU за одним коммутатором делят одно PCIe5 x16 подключение к CPU (128 GB/s), что создаёт узкое место при одновременной передаче данных
- Усложнённая поддержка GPUDirect RDMA: дополнительный hop через PCIe switch может ухудшить производительность GPUDirect, особенно для GPU-to-GPU через сокеты
- Увеличенное энергопотребление: дополнительные активные компоненты (PCIe switches) потребляют дополнительную энергию
- Потенциальные проблемы с PCIe топологией: пересечение межсокетной шины (Infinity Fabric/QPI) через PCIe switch может привести к серьёзным ограничениям производительности (250 MB/s - 1.1 GB/s в некоторых направлениях)
Использование технологий NVIDIA GPUDirect
GPUDirect RDMA с InfiniBand
GPUDirect RDMA позволяет InfiniBand адаптерам напрямую обращаться к памяти GPU, минуя CPU и системную память.
Дизайн 1 (преимущество):
- Прямое подключение GPU к CPU и InfiniBand адаптера к тому же CPU обеспечивает оптимальный путь данных
- Латентность GPUDirect RDMA: 1.7-2 мкс для небольших сообщений
- Пропускная способность: до 6-7.4 GB/s при использовании PCIe switch в той же секции, но может достигать близко к FDR peak (6.1 GB/s) при оптимальной топологии
Дизайн 2 (недостаток):
- Дополнительный PCIe switch в пути данных увеличивает латентность и может снизить эффективность GPUDirect
- Пересечение межсокетной шины через PCIe коммутатор приводит к драматическому падению производительности (250 MB/s для write, 1.1 GB/s для read)
GPUDirect P2P (Peer-to-Peer)
Внутри каждой группы из 4 GPU:
- Оба дизайна эквивалентны: NVLink 4-way bridge обеспечивает 900 GB/s bandwidth per GPU
- NVLink предпочтителен для P2P коммуникации внутри группы, так как обеспечивает в 7 раз большую пропускную способность по сравнению с PCIe Gen5
Между группами GPU:
- Дизайн 1: GPUDirect P2P через CPU работает лучше благодаря прямому подключению и Infinity Fabric
- Дизайн 2: дополнительные PCIe switches в пути значительно ухудшают производительность P2P между группами
Оптимальность для задач AI
Инференс больших моделей с model parallelism
Требования:
- Модели требующие более 564 GB памяти (4x141GB) должны быть разделены между двумя группами GPU
- Tensor parallelism требует частой синхронизации между всеми GPU
- Критична низкая латентность для обмена активациями между слоями
Рекомендация: Дизайн 1
Tensor parallelism требует коммуникации после каждого слоя модели, что делает латентность критичным фактором. При TP=8 (все 8 GPU), требуется синхронизация между двумя группами GPU:
- Дизайн 1: латентность 15-25 мкс для GPU-to-GPU через CPU
- Дизайн 2: латентность 400-500 нс только для traversal через switches, плюс время передачи данных
Для инференса, где каждый token требует forward pass через всю модель, накопленная латентность Дизайна 2 будет значительно хуже.
Fine-tuning (тренировка) больших моделей
Требования:
- Backward pass для градиентов требует интенсивной коммуникации
- AllReduce операции для синхронизации градиентов
- Pipeline parallelism может снизить требования к bandwidth между группами
Рекомендация: Дизайн 1 (с оговоркой)
Для tensor parallelism в тренировке: Дизайн 1 значительно лучше из-за низкой латентности.
Для pipeline parallelism: разница менее критична, так как PP передаёт активации только на границах stage, не требуя постоянной синхронизации. В этом случае оба дизайна работают приемлемо, но Дизайн 1 всё равно предпочтителен.
Для 3D parallelism (DP + PP + TP): Дизайн 1 обеспечивает лучшую общую производительность благодаря минимизации коммуникационных накладных расходов.
Связь между группами GPU: CPU vs InfiniBand
Через CPU (Infinity Fabric)
Пропускная способность: 37.9-42.6 GB/s bidirectional Латентность: 130-241 нс для межсокетного доступа Преимущества:
- Низкая латентность для небольших сообщений
- Прямой доступ к CPU памяти и кэшам
- Поддержка когерентности памяти
- Естественная интеграция с NUMA архитектурой
Через InfiniBand 400Gbps
Пропускная способность: 400 Gbps = 50 GB/s per direction Латентность GPUDirect RDMA: 1.7-5 мкс Преимущества:
- Выше bandwidth, чем Infinity Fabric (50 GB/s vs 37.9-42.6 GB/s)
- Обход CPU для GPU-to-GPU коммуникации
- Оптимизирован для RDMA операций
Вердикт: CPU (Infinity Fabric) более оптимален
Несмотря на то, что InfiniBand предлагает немного большую пропускную способность (50 GB/s vs 42.6 GB/s), связь через CPU является более оптимальной по следующим причинам:
- Значительно более низкая латентность: 130-241 нс через Infinity Fabric против 1.7-5 мкс через InfiniBand RDMA
- Для tensor parallelism латентность критичнее bandwidth: синхронизация после каждого слоя требует низкой латентности, не высокой пропускной способности
- NCCL автоматически выбирает оптимальный путь: библиотека NCCL (используемая PyTorch и другими фреймворками) автоматически выберет PCIe/Infinity Fabric для intra-node коммуникации и InfiniBand для inter-node
- InfiniBand лучше использовать для inter-node: InfiniBand оптимален для связи между физически разными серверами, не между группами GPU внутри одного сервера
Итоговые рекомендации
Дизайн 1 (Прямое подключение к CPU)
Рекомендуется для задач, где хватает одного сервера.
Оптимален для:
- Инференс больших моделей с tensor parallelism (TP=8)
- Fine-tuning с высокими требованиями к латентности
- Приложения, требующие минимальной латентности GPU-to-GPU
- Использование GPUDirect RDMA с максимальной эффективностью
Ключевое преимущество: минимальная латентность для синхронизации между группами GPU при использовании tensor parallelism.
Дизайн 2 (PCIe коммутаторы Broadcom)
Не рекомендуется для AI тренировки/инференса
Рекомендуется для этих же задач при кластеризации (использовании более одного сервера)
Может быть приемлем для:
- Pipeline parallelism с большими micro-batch размерами
- Сценарии, где GPU группы работают независимо
- Применения, требующие гибкой конфигурации PCIe устройств
- При необходимости использовании более, чем одного сервера (кластеризации)
Критические недостатки: увеличенная латентность и bottleneck upstream подключения делают этот дизайн субоптимальным для большинства AI workloads.
Использование InfiniBand адаптеров
InfiniBand 400Gbps адаптеры следует использовать для inter-node коммуникации (между физически разными серверами), а не для связи между группами GPU внутри одного сервера. Внутри сервера оптимальна связь через CPU с использованием Infinity Fabric.
Архитектурный анализ серверов на базе Intel Xeon 6700P
В этом сценарии рассмотрим процессоры “Mainstream” сегмента (сокет LGA 4710), такие как Xeon 6780P или 6756P.
Краткий вывод
Дизайн 1 (Прямое подключение к CPU) является единственным правильным выбором для этой платформы, но с оговоркой: у нас остается критически мало свободных линий PCIe.
Дизайн 2 (через коммутатор) здесь категорически неэффективен. Из-за того, что процессоры Xeon 6700P имеют мощную межсокетную связь (UPI), но подключаются к коммутатору всего одной линией PCIe x16, мы искусственно “душим” производительность всей группы из 4-х GPU при попытке передать данные на соседний процессор.
Детальное сравнение архитектур
Дизайн 1: Прямое подключение GPU к CPU
Архитектура:
- CPU: 2x Intel Xeon 6700P (Granite Rapids-SP).
- PCIe линии: В двухсокетной конфигурации каждый процессор предоставляет 88 линий PCIe 5.0.
- Важно: Это меньше, чем у 6900P (96 линий) и AMD EPYC 9005 (128+ линий).
- Потребление:
- 4 x GPU (x16) = 64 линии.
- 1 x IB 400G (x16) = 16 линий.
- Итого занято: 80 линий из 88 доступных.
- Остаток: Всего 8 линий на процессор. Этого хватит только для пары загрузочных NVMe дисков (x4) и базового управления. Подключить дополнительные NVMe массивы для кэширования данных уже не получится без дополнительных коммутаторов.
Межсокетная связь (UPI):
- Процессоры Xeon 6700P имеют 4 линка UPI 2.0 (против 6 у серии 6900P).
- Скорость: 24 GT/s на линк.
- Агрегированная пропускная способность: ~96-100 ГБ/с (полезной нагрузки в одну сторону).
- Это все еще в 2 раза быстрее, чем InfiniBand 400G (50 ГБ/с).
Сильные стороны:
- Максимальная утилизация межсокетной шины: 4 GPU могут одновременно отправлять данные на другой сокет с суммарной скоростью до ~100 ГБ/с (ограничено UPI).
- Низкая латентность: Прямой путь данных.
Слабые стороны:
- Дефицит расширения: Система получается “закрытой”. Свободных линий для добавления storage-адаптеров почти нет.
Дизайн 2: PCIe коммутаторы Broadcom
Архитектура:
- 4 GPU и 1 сетевая карта висят на коммутаторе PEX89144.
- Коммутатор подключен к CPU одним линком PCIe 5.0 x16.
Критический недостаток (узкое место Uplink):
В этой схеме все 4 GPU “борются” за одну линию PCIe x16 (64 ГБ/с), чтобы передать данные на соседний CPU.
- В Дизайне 1 пропускная способность между группами GPU составляла ~100 ГБ/с (лимит UPI).
- В Дизайне 2 пропускная способность падает до 64 ГБ/с (лимит Uplink x16), так как все данные должны пройти через узкое горлышко между коммутатором и CPU.
Это делает Дизайн 2 бессмысленным: мы используем дорогие GPU и мощные CPU, но соединяем их “тонкой трубочкой”.
Рекомендация для Intel Xeon 6700P
Выбирайте Дизайн 1 (Прямое подключение).
Даже с учетом меньшего количества линий UPI (4 шт.) по сравнению с топовой серией, связь через CPU все равно значительно быстрее и эффективнее, чем использование коммутатора с одним аплинком.
Связь двух групп ускорителей:
- Через CPU (UPI): Оптимальна. Обеспечивает ~100 ГБ/с пропускной способности.
- Через InfiniBand: Субоптимальна (50 ГБ/с). Используйте IB только для связи между серверами.
Станислав Обидин, itexperts.team
Права
Данный документ написан Станиславом Обидиным, в рамках работы в компании OpenYard (ООО «Центр открытых разработок»).
Является собственностью компании OpenYard (ООО «Центр открытых разработок»).
Использование части (цитирование) или целого документа допускается только с согласия и указании OpenYard (ООО «Центр открытых разработок»).
OpenYard